李宏毅老师好评!
Pre
优化方法:
Stochastic Gradient Descent 随机梯度下降 Update for each example
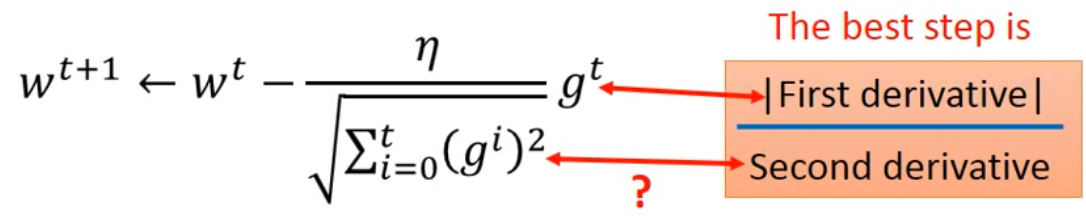
Normalize归一化:Make different features have the same scaling.

一次函数逼近

Optimization for deep learning
SGDM(momentum):累积之前的动量,避免SGD一遇到局部最小值就无法移动。
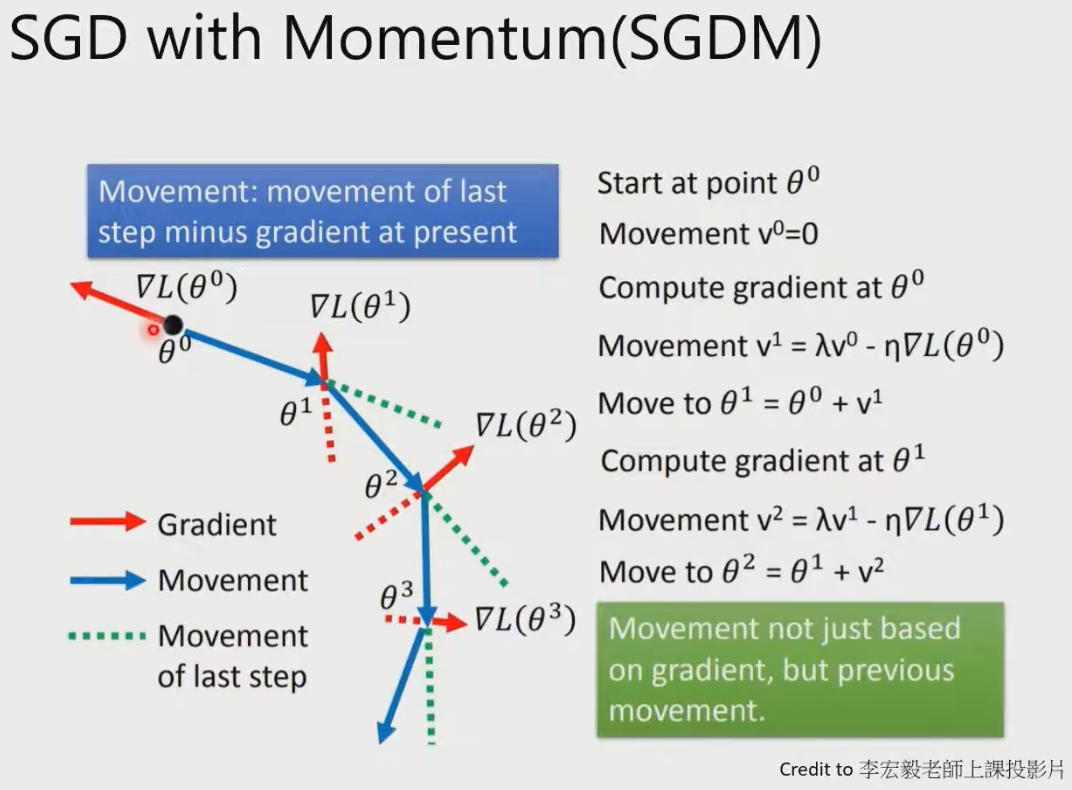
Adagrad:防止前几步走的太大。或者走一大步走过头了。
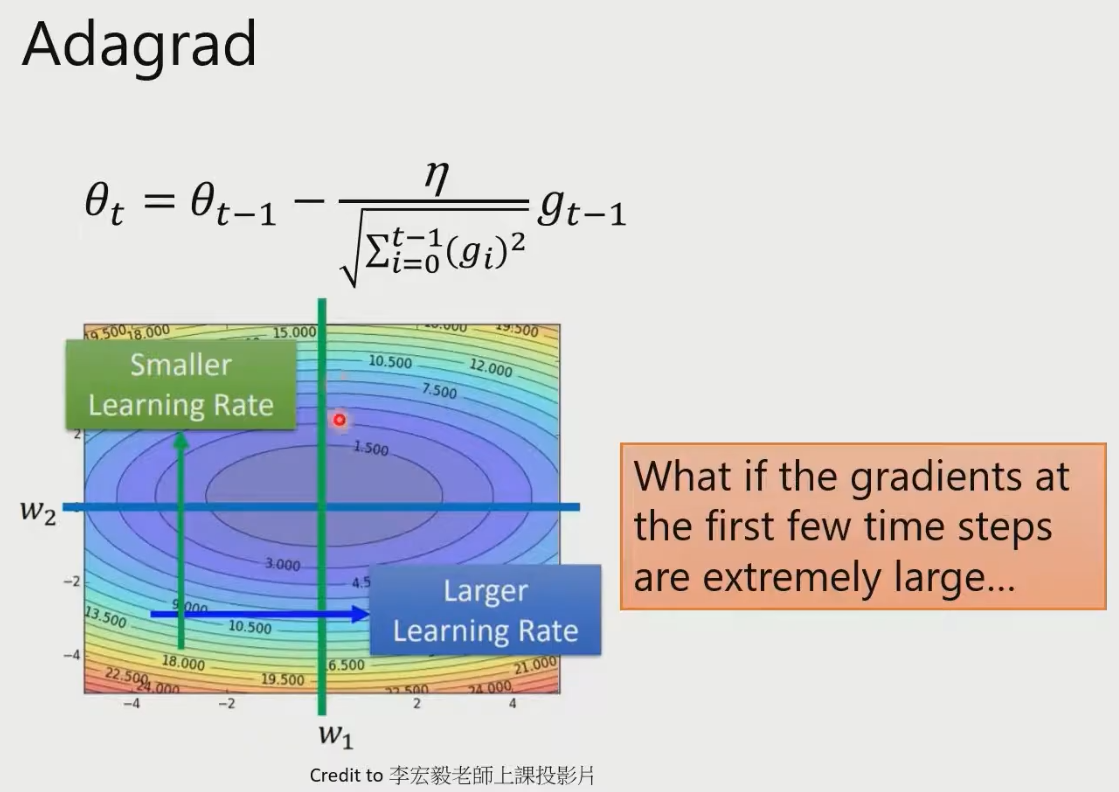
RMSProp:和Adagrad很像。Adagrad无限累加,之后learning_rate会很小。于是换了计算方法。
Adam:结合以上两种方法。
加hat的原因:刚开始
没有累积起来,比较小,除以
来手动扩大。
作者建议:


一个不太科学的结合方法:
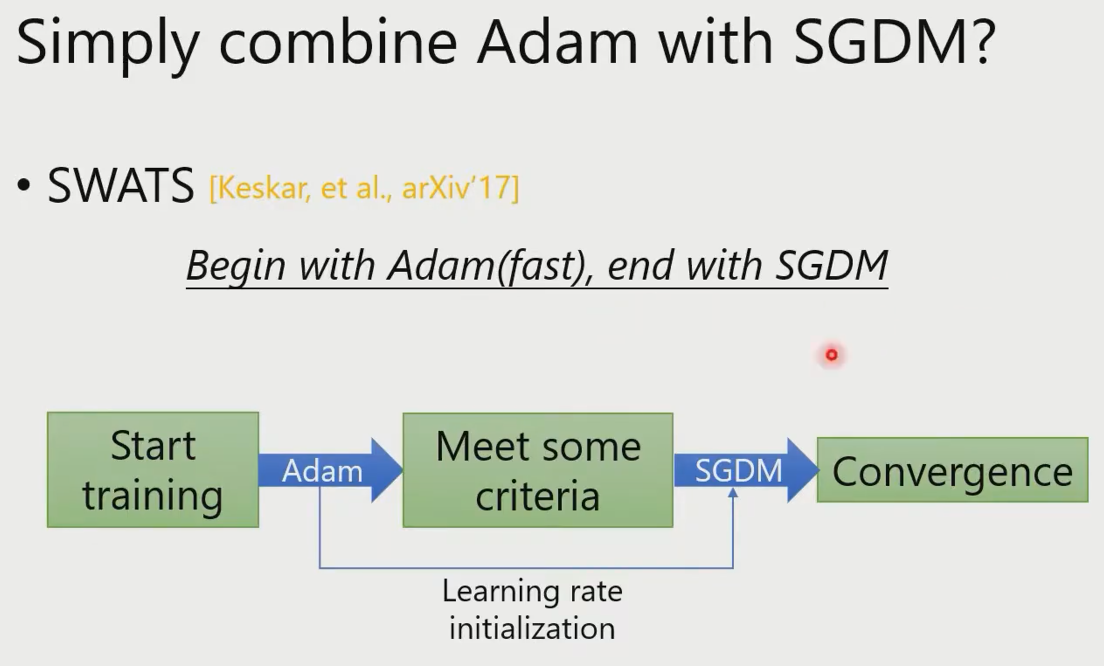
找出问题
把两种算法结合起来
用一些没有道理的,自己勉强能够解释的,实际有效果的方法
贪心等简单算法
L2 Optimization时,最好只在更新时考虑weight.




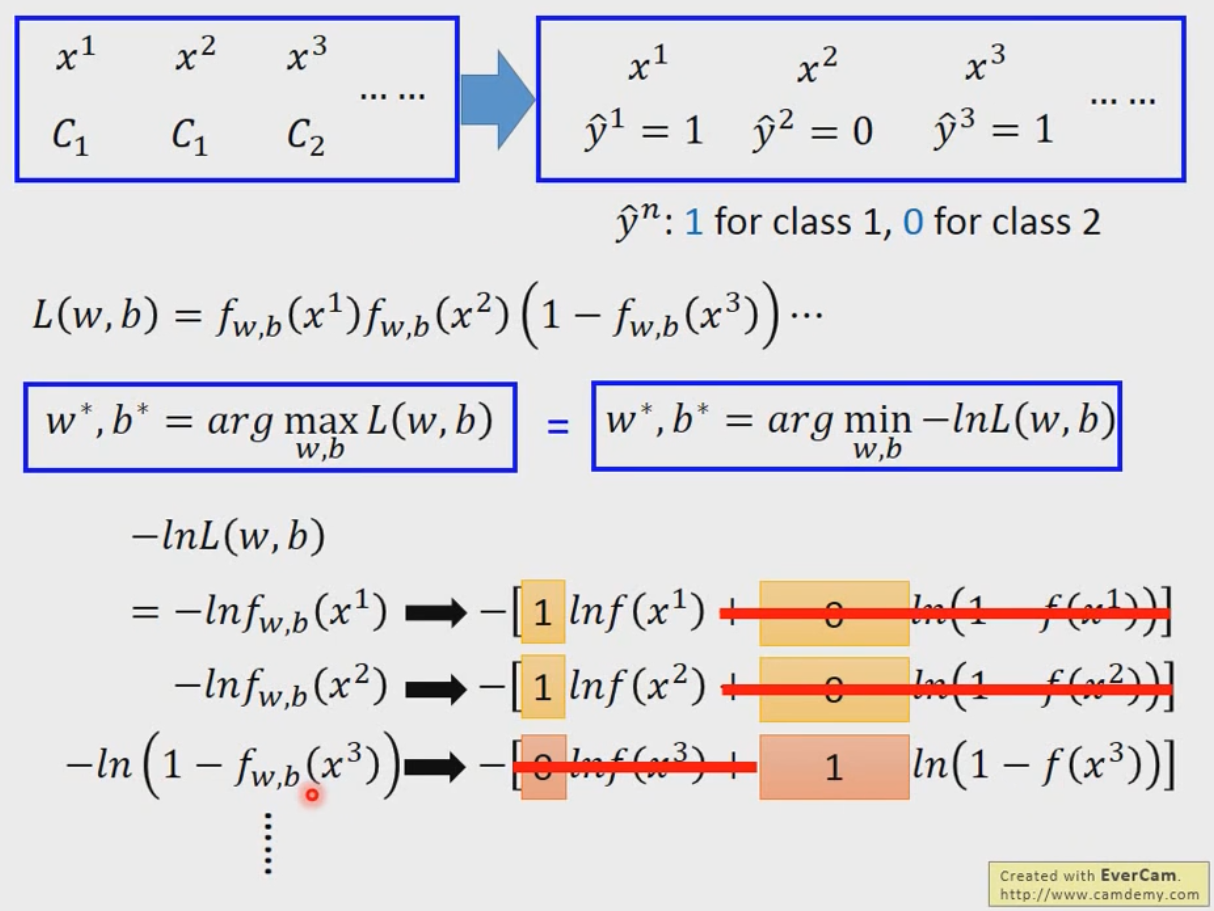
Logistic Regression
Classification利用Bayes来做
Sigmoid函数的来源是Bayes
CrossEntropy交叉熵,就是最大化正确的概率

Deep Learning
激活函数:
ReLU, Maxout
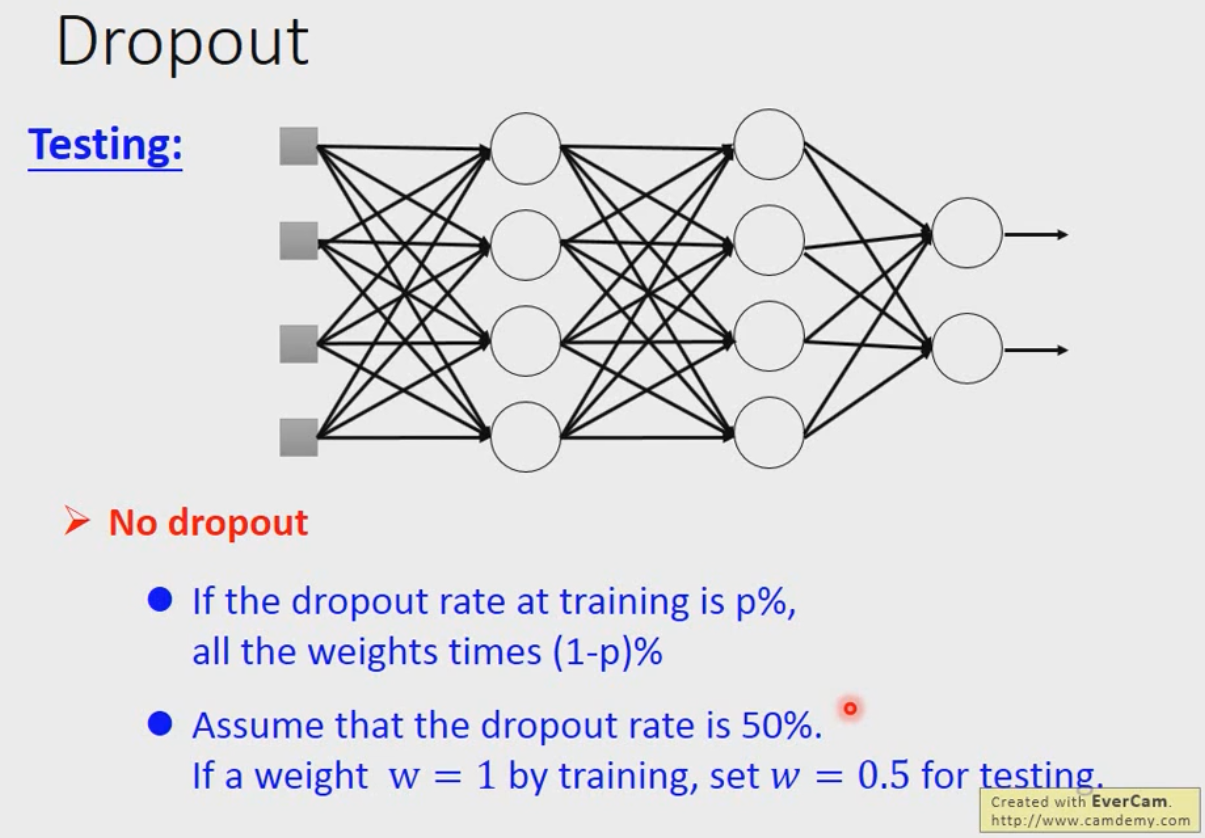


瞎想:能不能给图片加权重,以指出哪里是目标物体,以再次学习?
研究者:我猜会遇到这种情况,我猜这种情况能够更好的处理,试了试确实变好了,但是这真的是最好的吗。
ReLU局部是线性的,这好吗
apex.amp
torch.backends.cudnn.benchmark = true
CNN不见得能够处理不同scale的物体
EP8,9,17 are very useful!
ELU,SELU,GELU
GNN
类似于Audio,有两个思想,即时域和频率上做NN.
时域上,常用GAT
频率上,常用GCN,C表示Convolution. 如何在图上卷积?我们将拉普拉斯矩阵()对角化
,这时的
就类似于FFT中的范德蒙德矩阵。
使用切比雪夫多项式优化ChebNet。免去每次都矩阵乘向量,只需要向量相减,省去一维复杂度。
GCN实际上是把相邻节点的权值包括自己相加求平均再经过线性层和非线性层。
GAT效果常比GCN好。
RNN
simpleRNN
LSTM(Long Short-term Memory) 3 gates
GRU(Gated Recurrent Unit) 2 gates
Many to one: Sentiment Analysis, Key Term Extraction
Many to Many: Speech Recognition, Machine Translation
TODO:
nn.train(),eval()