开始看书!
(朱军推荐过的另一本书:Pattern Recognition and Machine Learning,一个著名论文Pay Attention to MLP)
Part I: Applied Math and Machine Learning Basics
线性模型无法学习XOR运算。
Probability
高维高斯分布:其中是正定实对称阵,给出n个变量的协方差。
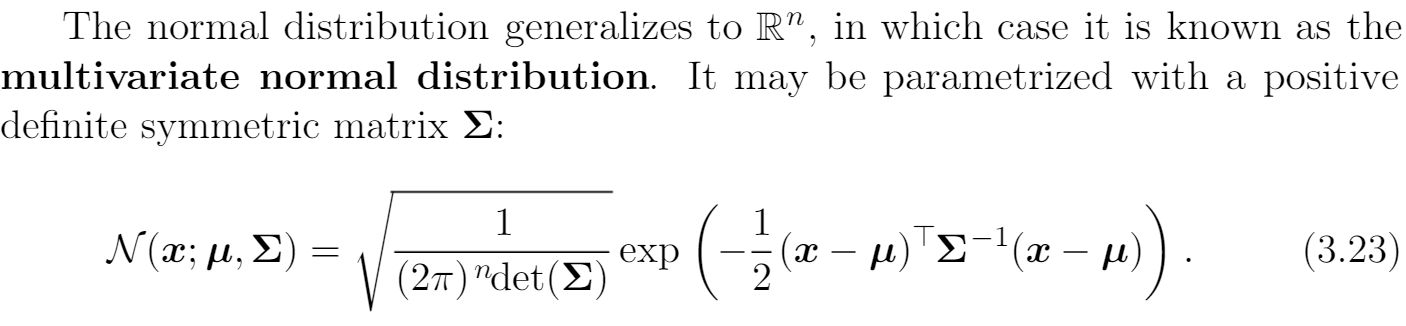
高斯混合模型:
-
是高斯分布,其中c是隐变量。
Some mixtures can have more constraints. For example, the covariance could be share across components via the constraint
.
-
: prior probability
-
: posterior probability
-
任意分布可以由足够多的高斯分布拟合到任意精度。
logit:
- log-it,对数几率
- 是odds的log,其中odds
测度理论:
- 数学分析
- 巴拿赫-塔斯基定理:在选择公理成立的情况下,可以将一个三维实心球分成有限(不可测的)部分,然后仅仅通过旋转和平移到其他地方重新组合,就可以组成两个半径和原来相同的完整的球。
Jacobian matrix:
- 数学分析
- 描述了非线性坐标变换
Information Theory
Self-infomation:
- unit: nat
Shannon entropy:
Kullbacj-Leibler (KL) divergence:
- not symmetric
Cross-entropy:
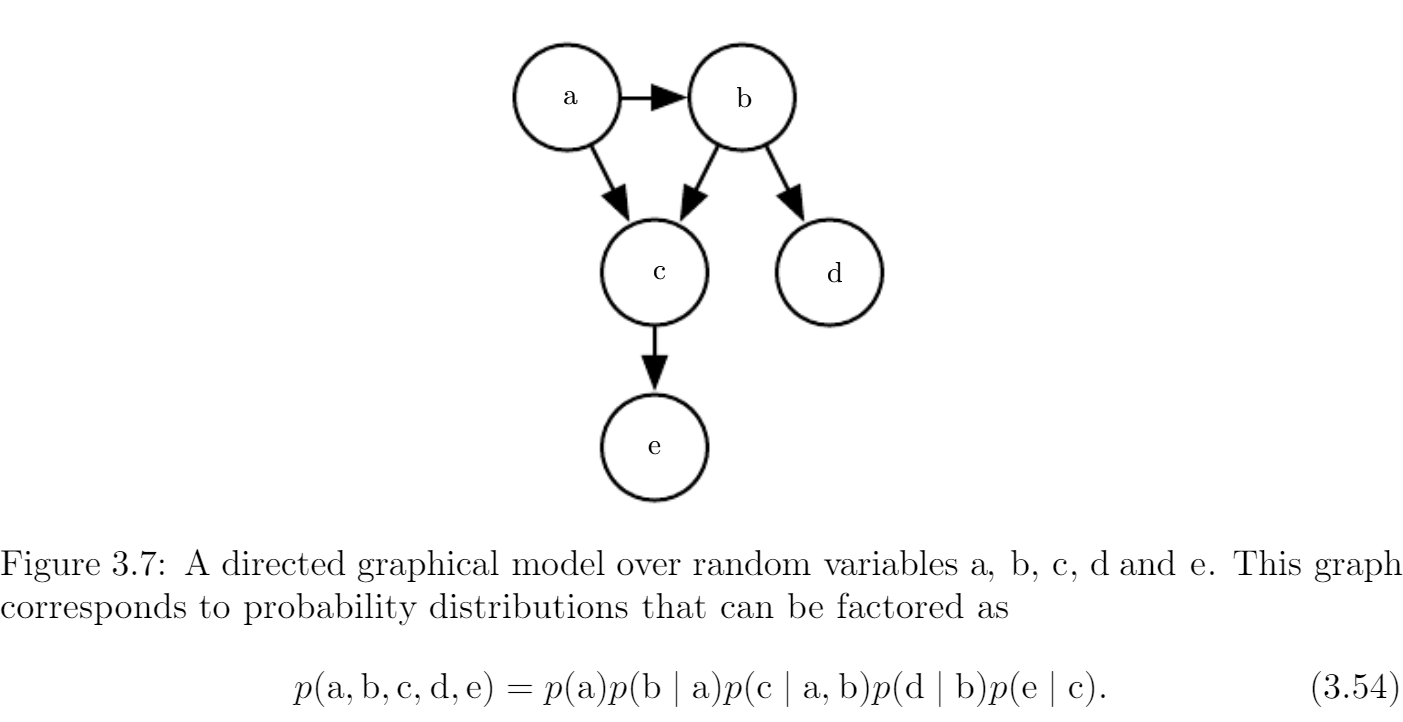
Structured probabilistic model:
-
directed
![image-20210802114025577]()
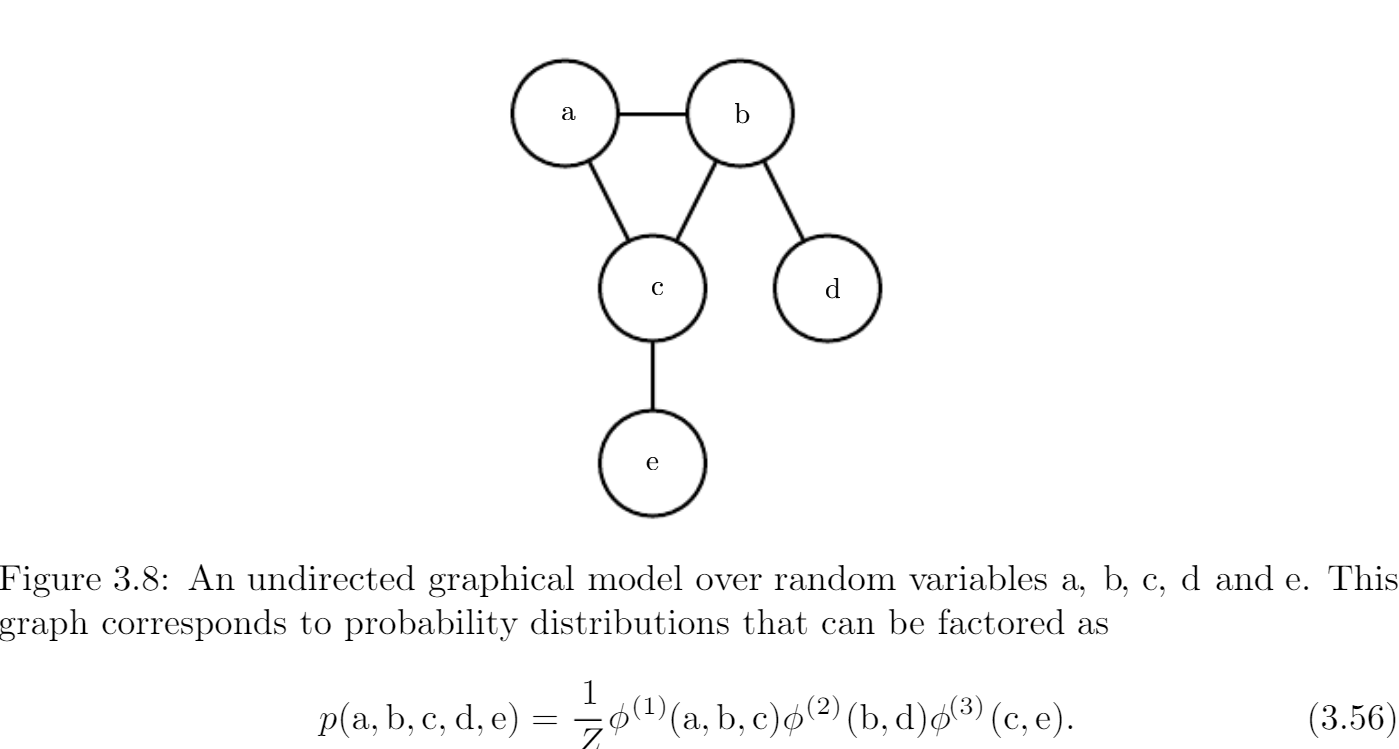
-
undirected
![image-20210802114038154]()
Numerical Computation
rounding error:
- accumulate
- underflow: ~0
- overflow: ~inf
- occur: exp in softmax
我们使用二阶Taylor series在处展开:
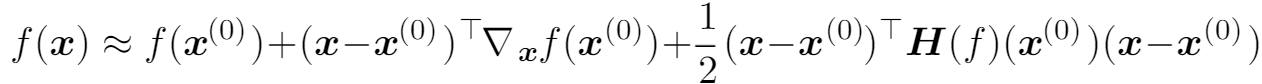
由于Hessian矩阵固定,因此我们可以解出临界点,这就是我们估算的极值点:
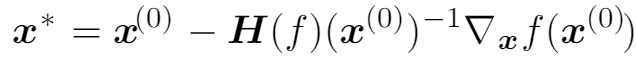
Optimization algorithms that use only the gradient, such as gradient descent, are called first-order optimization algorithms. Optimization algorithms that also use the Hessian matrix, such as Newton’s method, are called second-order optimization algorithms.
Constrained Optimization:
-
将gradient descent的step映射到定义域上
-
换元
-
拉格朗日乘子法(条件极值)
![image-20210802222002701]()
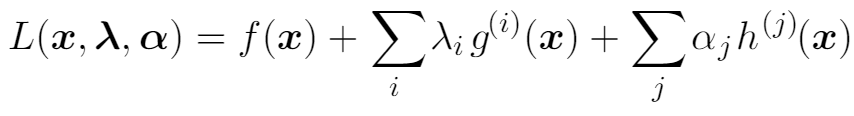
Machine Learning Basics
Tasks:
-
Classification
-
Classification with missing inputs
变量不能同时获得,如果有n个输入,就有
种获得信息的情况。
-
Regression: insurance premiums
-
Transcription: image, speech
-
Machine translation
-
Structured output: parsing, pixel-wise segmentation, image captioning
-
Anomaly detection
-
Synthesis and sampling: generate example, speech synthesis: there is no single correct output
-
imputation of missing values
-
Denoising
-
Density estimation
Performance measure
Experience: blurred boundaries
- supervised
- unsupervised:
- learn probability distribution
- synthesis
- denoising
- clustering
- semi-supervised
Capacity:
-
choose hypothesis space: linear, quadratic, or more
Machine learning algorithms will generally perform best when their capacity
is appropriate for the true complexity of the task they need to perform and the
amount of training data they are provided with.
-
奥卡姆剃刀
nonparametric models:
- nearest neighbor regression
- wrap a parametric learning algorithm inside another algorithm that increases the number of parameters as needed
Bayes error
The no free lunch theorem
Regularization is any modification we make to a learning algorithm that is intended to reduce its generalization error but not its training error.
k-fold cross-validation: One problem is that no unbiased estimators of the variance of such average error estimators exist (Bengio and Grandvalet, 2004), but approximations are typically used.